Lotus 源码研究 03 - 爆块优化和爆块 miner 分离的设计与实现
岸见一郎 -- 被讨厌的勇气
真正的问题不是挫折本身,而是你对挫折的反应。
转载声明
本文转载自原语云公众号 Lotus爆块优化和爆块miner分离的设计与实现 (opens new window)。欢迎订阅,第一时间获取技术干货。
本文属于原语云的分布式 miner 系列第一篇,这篇将重点介绍原语云的爆块 miner 分离的设计和实现以及原语云在 Lotus 爆块上的一些优化实践。
# 一、全功能单miner的痛点
单个全功能的miner的弊端估计绝大部分有lotus集群深度运维经验的人都会知道,时空证明这段时间GPU会被锁住 (看计算情况在2到十几分钟不等),如果这会你的集群的 IsRoundWinner 返回的 winner 不是 nil, 也就是你的集群被模型选中为参与爆块了,会因为获取不到GPU资源而丢掉这个块,因为这种情况下完成 WinningPost 计算绝对会超过30秒了,加上爆块tipset的baseDelta的时间,这个块肯定丢失了。
如果丢失会打印类似如下的 WARN 日志:
log.Warnw("CAUTION: block production took longer than the block delay. Your computer may not be fast enough to keep up",
"tPowercheck ", tPowercheck.Sub(tStart),
"tTicket ", tTicket.Sub(tPowercheck),
"tSeed ", tSeed.Sub(tTicket),
"tProof ", tProof.Sub(tSeed),
"tPending ", tPending.Sub(tProof),
"tCreateBlock ", tCreateBlock.Sub(tPending))
你可以通过运行如下bash程序来确认你的集群因为类似原因而导致的丢块记录:
grep "block production took longer" miner.log文件
# 二、GPU资源抢占的解决方案
对于上述描述的GPU资源抢占的情况,基本上有如下两种优化思路:
# 2.1 分别绑定GPU计算:
全功能miner上接入两个及以上的GPU,更改rust层代码响应BUS ID的绑定,例如:两个GPU,绑定至少一个GPU单独用作爆块证明加速计算,剩下的GPU用作时空证明加速计算。 这样在时空证明计算过程中,即使被选中参与爆块也不会影响WinningPost的计算加速。
# 2.2 使用独立的WinningPost计算机器:
使用独立的miner机器来单独运行爆块程序保持和时空证明miner的硬件隔离,这样任何时刻的WinningPost计算都不受时空证明计算的影响,也可以很方便的在这台机器上单独做WinningPost的优化。
原语云从一开始就是直接选择了上述的第二种优化思路,以下开始讲述整个WinningPost miner分离方案的设计思路和具体的实现。
# 三、分布式miner的架构设计
原语云的整个分布式miner的架构如下,其中一个miner叫做root miner (根miner)专门负责扇区信息的存储和索引。
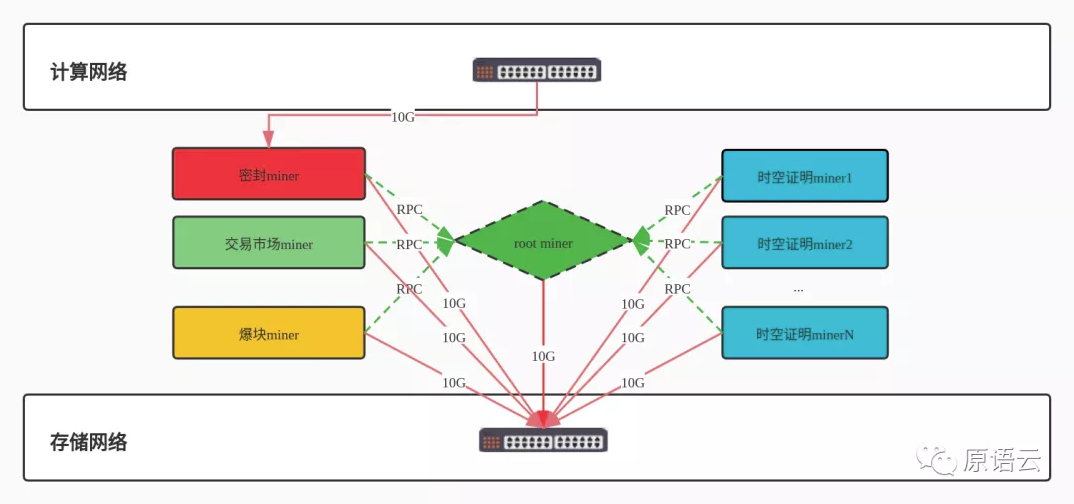
root miner专门用于管理扇区信息的存储和索引,目前原语云的大部分客户的root miner、密封 miner、爆块 miner、交易市场 miner 都是跑在一台 miner 物理机器上, 最多的是将爆块miner进行了硬件分离,整个架构支持按需分开和随时拓展,尤其是有效算力到了几十P,需要“时空证明miner”集群来参与时空证明的计算。
# 四、爆块miner分离的实现
整个WinningPost miner分离的实现主要需要如下三步核心工作:
# 4.1 WinningPost计算的开关
root miner和WinningPost miner的分离等同于运行了两个miner进程,而且是独立在两台物理机器上,第一步工作是给miner程序增加一个WinningPost计算的开关,实际运行过程中root miner关闭WinningPost计算, 而WinningPost miner打开WinningPost计算,这样来确保两个miner进程不会同时进行WinningPost计算,原语云的lotus分支增加一个MinerTaskConfig结构体来存储计算任务的配置:
type MinerTaskConfig struct {
ApiPolicy StorageApiPolicy
WinningPost bool
WindowPost bool
PostOffset uint64
PostIndex uint64
SealingMgr bool
SectorStore bool
DealsMgr bool
}
原语云产品的交互是通过SaaS平台的应用的来部署多miner方案:

所以我们抛弃了config.toml文件的配置形式,主要是在lotus-miner的run.go里面通过flag参数来初始化,本身还可以通过环境变量的来局部覆盖,初始化逻辑如下:
apiPolicy, err := config.ParseStorageApiPolicy(cctx.String("storage-api"))
if err != nil {
return xerrors.Errorf("Parser storage api policy, err: %w", err)
}
//创建和从cli flag参数初始化miner配置结构体
taskConfig := &config.MinerTaskConfig{
ApiPolicy: apiPolicy,
WinningPost: cctx.Bool("winning-post"),
WindowPost: cctx.Bool("window-post"),
PostOffset: cctx.Uint64("wdpost-offset"),
PostIndex: cctx.Uint64("wdpost-index"),
SealingMgr: cctx.Bool("sealing-mgr"),
SectorStore: cctx.Bool("sector-store"),
DealsMgr: cctx.Bool("deals-mgr"),
}
// 检测并且响应环境变量的覆盖
err = taskConfig.OverrideFromEnv() // check and override the config from env vars
if err != nil {
return xerrors.Errorf("TaskConfig override from env err: %w", err)
}
开关配置和初始化完成之后,重点就是miner构建的时候需要响应WinningPost的开关,依据配置在build.go中响应WinningPost相关的DI注入,具体查看下面的StorageApi的共享。
# 4.2 StorageApi的共享
WinningPost的计算程序的核心逻辑在miner/miner.go#mineOne里面,整个爆块计算过程中唯一的外在数据依赖就是扇区的存储信息,也就是运行 ComputeProof 计算的时候 rust 层需要知道挑战的扇区的cache和sealed文件的路径, 扇区的存储位置信息是通过 SectorIndex 来管理的,SectorIndex的Api本身也是 api storage的子集,也就是 WinningPost miner只要通过RPC共享 root miner的 storageApi 就可以实现存储信息的共享了,代码实现如下:
连接 root miner 获取 storage 的RPC接口:
var closer func() for { // 通过api和token文件授权的形式连接root miner并且返回storage api的rpc接口 storageApi, closer, err = lcli.GetMinerAPI(cctx, repo.RootMiner, cliutil.StorageMinerUseHttp) if err == nil { _, err = storageApi.Version(ctx) if err == nil { break } } fmt.Printf("Connecting to main miner API... (%s)", err) time.Sleep(time.Second) continue } defer closer()DI 注入覆盖默认的 SectorIndex 创建:
有了上面获取的 storageApi 的RPC接口后,我们就可以使用远程的root miner的存储服务了,质押过程中新增扇区的信息也是同步的, 接下来要做的就是在创建miner节点的时候覆盖默认的本地 SectorIndex 的注入为上述的 storageApi 对象,具体实现如下:
stop, err := node.New(ctx, // 注册 taskConfig 到 storage miner node.StorageMiner(&minerApi, cfg.Subsystems, taskConfig), node.ApplyIf( func(s *node.Settings) bool { return s.TaskConfig.ApiPolicyIn(config.StorageApiShareIndex, config.StorageApiRemoteFully) }, // 覆盖SectorIndex的创建为上述连接的storageApi rpc接口实例 node.Override(new(stores.SectorIndex), storageApi), ), // 注入MinerTaskConfig的工厂 node.Override(new(*config.MinerTaskConfig), taskConfig), )
# 4.3 扇区存储的兼容对应
通过上述的RPC服务获取的扇区的存储信息都是root miner的配置,也就是返回的storage id都是root miner管理的 sectorstore 的信息,如果想要 WinningPost miner能够正确的转换扇区的存储信息为正确的本地路径, 还需要WinningPost miner和root miner的 storage 信息保持一致,简单来说 WinningPost miner和root miner的 storage.json 中配置的路径的需要保持对应一致(配置同样的sectorstore集合), 这样通过rpc返回的存储Id,在WinningPost miner机器上可以顺利得到挑战扇区的 sealed 和 cache 文件的本地路径而完成后续的 proof 计算。
经过上述改动后,时空证明和爆块证明的计算就分离在了不同的物理机器上,同时共享扇区的存储信息。
# 五、爆块的其他相关优化
除了上述的分离爆块计算到单独的miner机器以外,以下一些方法是原语云实践过的有利于减少丢块的方法:
# 5.1 daemon机器尽量使用BGP网络:
lotus网络是一个整体,整个网络的交易信息都是通过daemon节点来进行交互的,无论是你的消息的广播还是你接收其他节点的消息都是通过你的daemon的p2p连接。那就得回到网络运营商这个问题来了,大部分集群用的电信, 也有很多用的移动,也有用联通的,消息跨运营商交互肯定有一定延迟的,BGP路由本身可以极大的减少跨运营商的路由和传输延迟。这对减少丢块肯定有是有一定的促进作用的,尤其是让很多人费解的孤块。
# 5.2 cache存储加速:
PB级别的集群基本选型的是网络存储,如果在时空证明的密集型网络IO时段被选中爆快,ComputeProof 计算过程会因为网络读取的延迟而不确定性的拉长,网络存储的读写不比本地存储慢,但是 IO 并发能力还是差很多, 所以PB级别的集群建议都将扇区的 cache 文件缓存到高速的M.2/U.2磁盘阵列上, 原语云都会建议客户配置打开 cache 的自动缓存,便于并发读取的加速,这样爆块和时空证明计算时间都会得到大幅度的提升, 如下图,原语云某个客户的PB级别的集群爆快时间基本稳定在2秒上下:
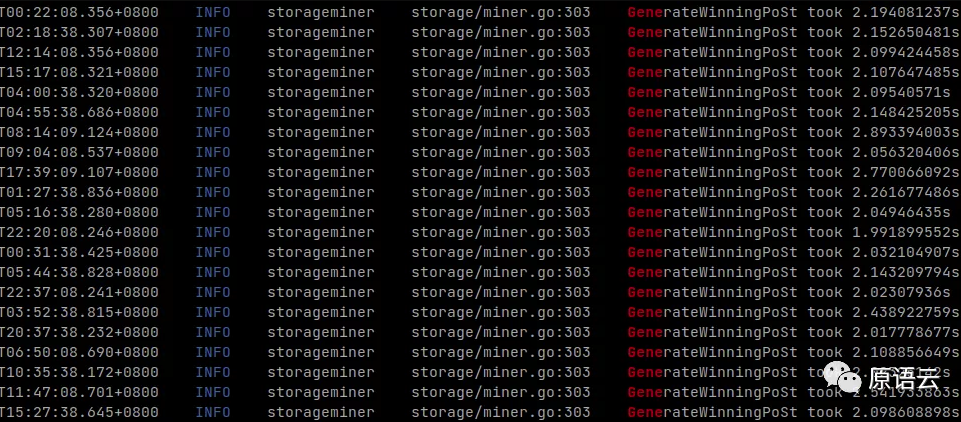
这比我本地512MiB的测试网络的爆块速度还快。
上述这些优化综合一起带来的效果也是比较正面的,例如原语云管理的某个近3PiB的集群使用上述优化运行一段时间后,丢块记录降为0,近期一段时间7天和30天的幸运值都大于了100%,提升了40%+:
7天爆块统计:
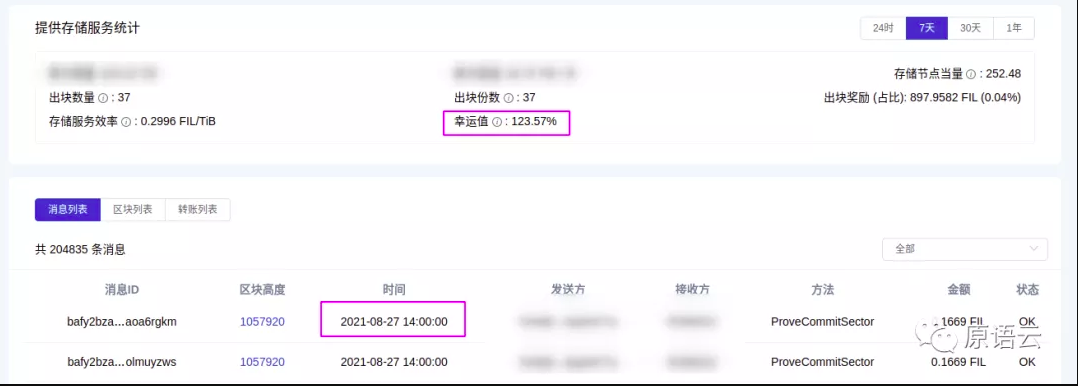
30天爆块统计:

更多优化方法将会在后续继续输出,欢迎探讨学习。
本文首发于原语云 (opens new window)公微信服务号。原语云是专注智能运维的SaaS云平台。提供海量服务器的可视化智能运维、Filecoin的集群方案/代码优化/可视化管理/应用生态等一站式云解决方案!
如果您觉得本文对您有用,可以请作者喝杯咖啡。 如需商务合作请加微信(点击右边链接扫码): RockYang


版权申明 : 本站博文如非注明转载则均属作者原创文章,引用或转载请注明出处,如要商用请联系作者,谢谢。