今天早上在知乎刷到AI研究员田渊栋老师的2025年度总结,其中关于未来人与AI关系的思考让我很受启发。
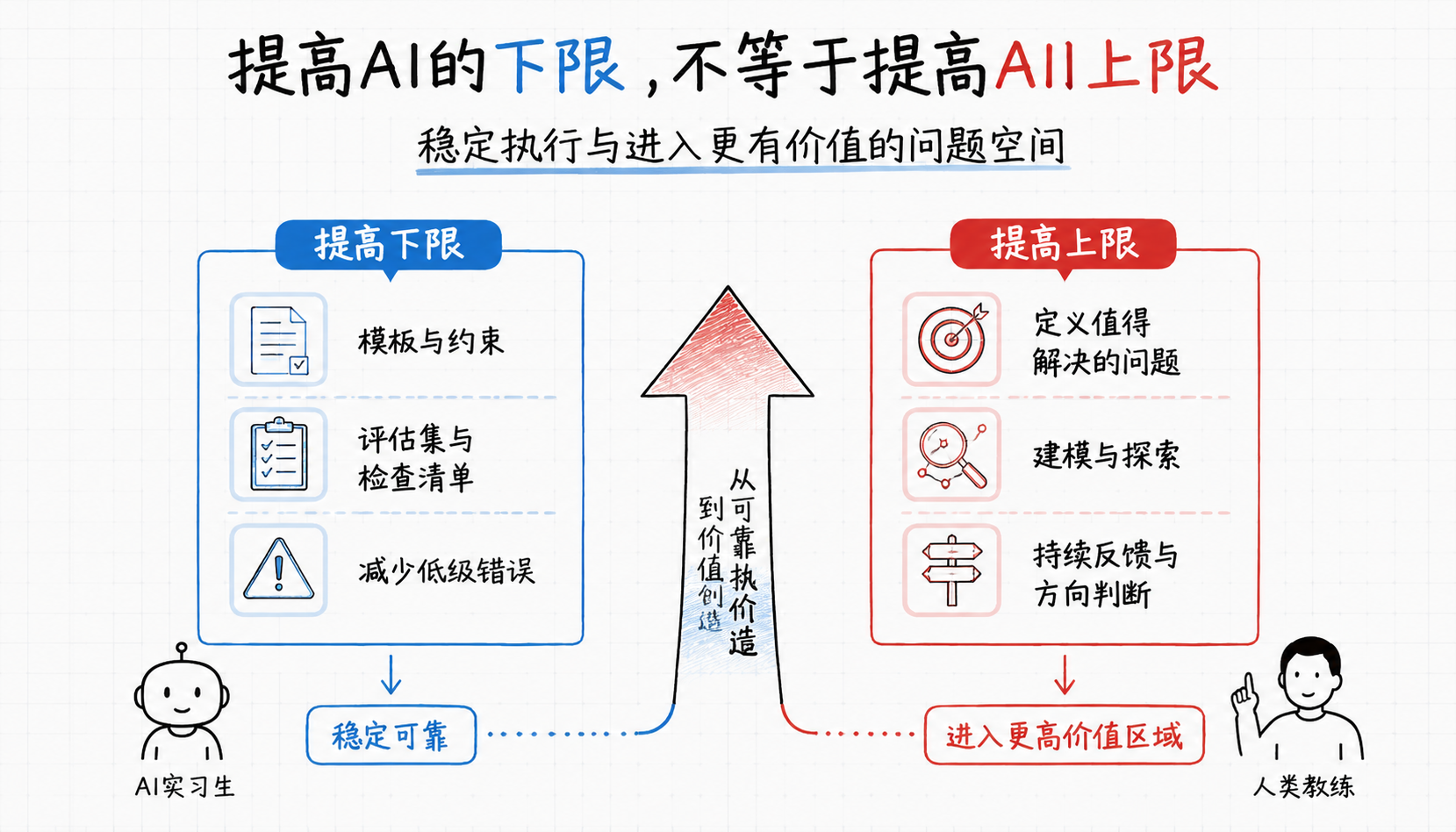
田老师提出:AI时代,人才价值的评估逻辑已经彻底改变。在传统的评估框架里,工作经验积累越多,能力越强,回报也越高,是一条稳定的单调上升曲线——这也是大厂设立职级体系的底层逻辑:职级随工作年限晋升,确实一度是「越老越吃香」。
但当下的情况已经完全不同:职级光环失效,过去的经验也不再是硬通货。人才价值的评判标准,已经从「评估劳动者本人产出的劳动数量与质量」,转变成了「人能否放大AI的能力」——只有「人+AI」的总产出大于AI单独的产出,这样的人才真正具备不可替代的价值。
一个人每天工作八小时,另一个人每天只工作两小时。只看劳动数量,前者似乎更有价值。
但在AI时代,可能恰恰相反。后者用两小时定义问题、拆解任务、设计流程、检查结果,再让AI连续运行十几个小时。最后创造更多价值的,未必是亲手完成最多动作的人,而是能让机器朝正确方向行动的人。
这里有一个反常识的判断。
AI降低了生成答案的成本,却没有降低判断答案的成本。
它让文字、代码、图像、表格和方案大量出现,却没有替你决定哪个问题值得回答,也没有保证答案适合你的场景。生成端越来越便宜,判断端反而越来越重要。
这篇文章想讨论的不是一句口号,而是一种工作模型。读完以后,你可以用一套二维标准判断自己的AI系统处在什么状态,也可以知道哪些能力需要从执行层上移到问题定义、流程架构和价值判断层。



作者视角:本文基于 2026 年 5 月公开融资信息与行业分析展开推断,不构成投资建议。未披露数据处已标明。
先说结论: 截至 2026 年 5 月,DeepSeek(深度求索,中国大模型公司,创始人梁文锋)投后估值超 3500 亿元人民币,买的不是当期收入,而是三件事——用开源 R1 打破美国 AI 行业的定价权锚点、在国家大基金背书下成为中国 AI 基础设施的候选建设者、以及能否建成正反馈闭环的不确定性溢价。23 天内估值从约 100 亿美元跃升至约 515 亿美元,反映的是行业定价体系相变,而非常规 PE 估值。

作者视角:本文基于近期大厂 AI 算力/API 聚合平台布局、运营商 Token 套餐趋势,以及中小 API 聚合平台关停现象展开分析。本文不构成任何投资建议。
先说结论:低价 API 中转的红利正在消退。 阿里云百炼、火山方舟、百度千帆、腾讯云、华为云及三大运营商 Token 套餐,正把 AI API 生意从草莽中转推向正规化算力平台——比的是合规、稳定、模型路由与开发者生态,而不是谁更便宜。对中小开发者:应假设底层成本会上升,竞争力从倒卖 Token 转向场景交付与 Token 成本工程;机会没有消失,而是从底层中转转向上层垂直场景。
API 聚合平台(也常被称为 API 代理、反代、聚合 API)指:在不直接签约各家模型厂商的前提下,将多模型调用、计费与风控聚合成单一 API 入口,再转售给开发者或企业的二级聚合服务。



你有没有想过一个细思极恐的问题:你去急诊,分诊台后面坐着的,可能不是人。
这不是科幻。这是哈佛医学院上周发表在《Science》上的一项研究——OpenAI 的 O1 推理模型,在急诊分诊诊断中的准确率达到了 67%,而跟它对阵的两位主治医师,只有 50% 和 55%。
67% vs 50%。
在生死攸关的急诊分诊环节,AI 赢了。

极客学长
171
文章
342
标签

置顶
- Mybatis 源码学习笔记
- Spring 学习总结
- Spring MVC源码学习笔记
- Spring 事务源码学习笔记
- Spring AOP 源码学习笔记
- MySQL8.0 重置密码
- Lotus 多重签名钱包使用详解
- Lotus 私钥安全防护
- Lotus snap-deal 功能体验报告
- Lotus 源码研究 06 - CC 扇区恢复功能的设计与实现
分类
- Database 7
- 技术杂谈 21
- Docker 4
- Jekyll 1
- 前端开发 7
- FunnyTools 8
- 随笔杂谈 12
- PHP 5
- 读书笔记 7
- Java 9
- SpringBoot 4
- 区块链技术 15
- IPFS 5
- C/C++ 1
- Filecoin 32
- Golang 2
- Sharding-JDBC 3
- 分布式存储 11
- Lotus-源码系列 8
- Spring-源码系列 4
- 框架源码系列 1
- AI 23
- ChatGPT 4
- Lotus 1
- DeepSeek-R1 1
- DeepSeek-V3 1
- Stable Diffusion 2
- 商业 3
- 工具 2
- 缩放定律 1
- 编程 2
- 教育 1
- 大模型 2
- 创业 2
- 逆向学习法 1
- 递归学习 1

