3.5元 vs 30元:DeepSeek V4凭什么用十分之一的价格叫板Claude和GPT?
4 月 16 号,Anthropic 发了个 Claude Opus 4.7。4 月 23 号,OpenAI 紧跟着发了个 GPT-5.5。4 月 24 号,DeepSeek 又蹦出来个 V4。
9 天之内,三家先后出牌,全部百万 token 上下文,全部主打 Agentic 能力。
我看完了这三场发布会的感觉就是,之前那种「谁是最强模型」的讨论,好像突然变得没意义了。
不是因为谁碾压了谁。
恰恰相反,是因为谁也没碾压谁。
三足鼎立了。
# 一、Claude Opus 4.7:深度审查官
先聊聊这三个模型各自干了什么。
# 编程能力跃升
Claude Opus 4.7,4 月 16 号发布的,Anthropic 最新的旗舰。
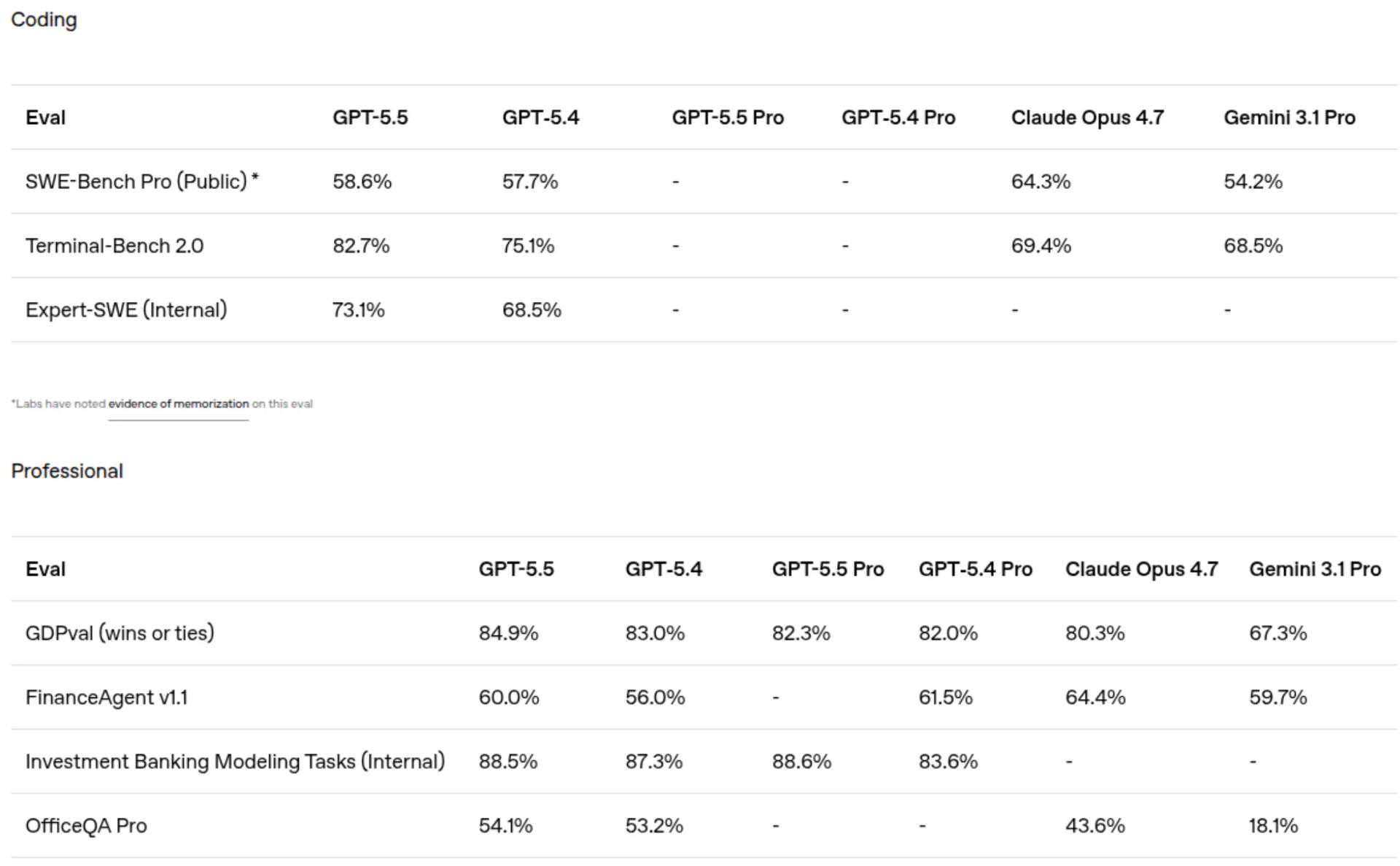
这玩意在软件工程上提升特别大。有个专门测试 AI 能不能修真实 bug 的考试叫 SWE-Bench,就好比程序员面试里的实操环节,不是考你会不会背语法,而是给你一个真实的 bug 让你修。Claude 在这个考试里拿到了 72.0%。
啥概念呢,就是给它一个真实的 GitHub 项目,里面有个 bug,它能自己找到问题、自己写修复代码、自己测试验证,整个过程几乎不需要人插手。
# 视觉能力大升级
它有个让我特别感兴趣的地方,是视觉能力。之前 Claude 看图就像戴着老花镜看手机,糊糊的。这次 Opus 4.7 直接摘了眼镜,支持了 3.75 百万像素的高分辨率图片,是之前 3 倍以上。你给它一张密密麻麻的电路板照片,它能看清每根线。
98.5%是个什么概念呢,就是 100 张图里只有一两张可能看走眼,几乎和人一样靠谱了。
# 安全先行
还有一个比较骚的事,Anthropic 手里其实有个更强的模型叫 Claude Mythos,但因为网络安全风险太大,他们选择了不放出来,先在 Opus 4.7 上测试安全措施。
这个做法。。。我有时候觉得,这才是真正负责任的态度。你手里有大杀器,但你选择先学着怎么安全地握住它,而不是直接丢到市场上。
安全,安全,还是他妈的安全。
# 二、GPT-5.5:自主执行者
# Agentic 自主执行
GPT-5.5 呢,4 月 23 号发的,OpenAI 定位是「迄今最智能最直觉的模型」,重点在 Agentic 自主执行上。
啥叫 Agentic 自主执行呢,就是不是你问它一句它答一句,而是你丢给它一个任务,它自己规划、自己找工具、自己执行、自己检查结果,全程不用你盯着。
有个专门考这个的测试叫 Terminal-Bench,就是让 AI 在命令行里完成一连串复杂操作,就好比让一个实习生独立完成一个从调研到部署的完整项目,不是考单个命令,而是考整条链路能不能走通。GPT-5.5 在这个测试上拿到了 82.7%。
GDPval 做到了 84.9%,这个考试是拿 44 种职业的真实工作来考 AI,比如律师审合同、分析师写报告、医生看病历这种。84.9%就是 AI 在绝大多数职业里能跟人打平甚至赢了。
还有一个很有意思的测试叫 OSWorld,考的是 AI 能不能像人一样操作电脑桌面,打开软件、点按钮、填表格、拖文件这些。GPT-5.5 做到了 78.7%,你想想看,一个 AI 能像人一样操作你的电脑,而且准确率接近 80%。
# Token 效率:省了 72%
它还有一个很厉害但容易被忽略的优势,是 token 效率。
token 你可能不太熟,简单说就是 AI 读和写的「字数计价单位」。好比打车,不是按公里收费而是按「步数」收费,每走一步收一步的钱。AI 生成的内容越多,花的 token 越多,花的钱就越多。
GPT-5.5 在 Codex 里做编程任务,用的输出 token 比之前少了 72%。72%啊,就好比以前打车从北京到上海要花 1000 块,现在同一条路线只要 280 块,这不是省一点,这是省了一大半。省 token 就是省钱,而且速度快了,因为写的东西少了。
# 价格与上下文
价格方面,API 输入$5/M token,输出$30/M token。还有个 Pro 版更贵,$30/$180。ChatGPT 里用的话 400K 上下文,API 里是 1M。
1M 上下文又是啥呢,就是 AI 能同时「记住」的内容量。1M token 大概相当于 75 万字,差不多是一整套《哈利波特》七部曲的总量。你把整个项目的代码和文档全扔进去,它都能记住,不会忘。
# 三、DeepSeek V4:开源性价比之王
# MIT 协议开源
然后是 DeepSeek V4。
4 月 24 号,MIT 协议开源,权重直接上了 HuggingFace。
开源啥意思呢,就好比闭源模型是成品药,你只能买成品吃,配方保密。开源模型是公开配方,你拿到配方之后可以自己在家做,可以改配方加料,可以把工厂搬到自己院子里生产。成本、自由度、安全性,全都完全不同。
# MoE 架构:大公司少干活
这玩意有两个版本。V4-Pro 是 1.6T 参数 49B 活跃,V4-Flash 是 284T 参数 13B 活跃。
啥叫 1.6T 参数 49B 活跃呢?
这叫 MoE 架构,就是混合专家系统。你可以这样理解,1.6T 参数就像一个有 16000 个专家的超大公司,但每次接到任务,只派 49 个最懂这个领域的专家去干活,其他人都在休息。
好处是啥呢,公司虽然大,但干活的人少,效率高、成本低。就好比一家律所有 1000 个律师,但你的案子只派 5 个最擅长这类案件的律师来服务,不需要 1000 个人全上阵。
V4-Flash 更极端,284T 参数 13B 活跃,就像一个精简版的快反小组,人更少,干活更快,便宜到你不敢相信。
# 价格:差一个数量级
💰 价格对比(/M token)
| 模型 | 输入价格 | 输出价格 |
|---|---|---|
| Claude Opus 4.7 | - | $25 |
| GPT-5.5 | $5 | $30 |
| DeepSeek V4 Pro | $1.74 | $3.48 |
| DeepSeek V4 Flash | $0.14 | $0.28 |
价格呢,V4-Pro $1.74 输入/$3.48 输出每百万 token,V4-Flash 更便宜,$0.14/$0.28。
你感受一下这个价格差距。
Claude Opus 4.7 输出$25/M,GPT-5.5 输出$30/M,DeepSeek V4 Pro 输出$3.48/M。
打个比方,同样让 AI 写一篇 10 万字的分析报告,用 GPT-5.5 大概要花 30 块,用 Claude 大概 25 块,用 DeepSeek V4 Pro 只要 3 块 5。
大概就是,GPT-5.5 跑一天的输出费用,DeepSeek V4 Pro 能跑 8.6 天。
这不是差一点,这是差一个数量级。
# 超长输出:一次写 28 万字
原生 1M 上下文窗口,最大输出 384K token,这个 384K 是目前所有模型里最高的。
384K 输出啥意思呢,就是 AI 一次回答最多能写 28 万字。其他模型最多只能写大概 10 万字就得停笔了,DeepSeek 能一口气写 28 万字。你让它写一本完整的技术手册,别的模型写一半就断了,它能从头到尾一气呵成。
# 四、技术深挖:混合注意力架构
聊完基本信息,再聊聊技术层面比较有意思的东西。
DeepSeek V4 最核心的技术创新是 Hybrid Attention Architecture,混合注意力架构。
听着挺学术的对吧。
我换个方式讲。
# 传统注意力的问题
想象你在看一本 1000 页的小说。
传统 Transformer 的注意力机制是怎么看这本书的呢,就是每翻一页,都要回头把前面所有页再扫一遍。读到第 500 页的时候,它要从第 1 页到第 499 页全部再过一遍,确认有没有什么重要线索。
读到第 900 页的时候呢,要从第 1 页到第 899 页全扫一遍。
你想想看,这个工作量是不是越来越恐怖?翻到后面的时候,光是回头扫描就累死了,根本没精力理解新内容了。
这就是为什么传统模型在超长上下文里会变慢、变贵、变笨。不是它不想认真看,是它看不动了。
# 三层注意力:局部 + 摘要 + 大纲
🧠 三层注意力架构对比
| 层级 | 名称 | 精度 | 比喻 |
|---|---|---|---|
| 第一层 | 局部窗口 | 全分辨率 | 手边几页逐字看 |
| 第二层 | CSA(压缩稀疏注意力) | 每 4 字压缩成摘要 | 前面几章看章节梗概 |
| 第三层 | HCA(重度压缩注意力) | 整本书压缩成大框架 | 脑子里留下的整体脉络 |
DeepSeek 的混合注意力架构换了一种看书方式,把注意力分成三层。
第一层是局部窗口,就好比你正在读的这一页和前后几页,逐字逐句全分辨率保留,每个字都看得清清楚楚。
第二层叫 CSA,压缩稀疏注意力。每 4 个字压缩成一个小摘要块,然后只检索跟当前内容相关的摘要。就好比你看小说,当前段落逐字读,但前面几章的内容你只看章节梗概,知道大致发生了什么就行。
第三层叫 HCA,重度压缩注意力。把整本书压缩成几个大框架块,只保留核心情节线和人物关系。就像你读完一本小说之后脑子里留下的东西,不是每句话,而是「主角从小村庄出发,经历了三次大战,最终成为国王」这种整体脉络。
三层叠加起来,就好比你在看一本 1000 页小说的时候,手边的几页逐字看,稍远的章节看摘要,整本书的脉络看大纲。三种精度同时存在,既不会遗漏重要细节,也不会被海量信息淹没。
# 效果:让百万 token 真正可用
⚡ 混合注意力效果对比
| 指标 | V4-Pro | V4-Flash |
|---|---|---|
| 推理计算量 | 27% | 10% |
| 缓存占用 | 10% | 7% |
效果有多猛呢,1M 上下文的推理计算量只需要之前的 27%,缓存只需要 10%。V4-Flash 更是只要 10%的计算量和 7%的缓存。
27%的计算量啥意思呢,就好比以前跑 1M 上下文需要 100 台服务器,现在只要 27 台。以前需要 100 块内存条,现在只要 10 块。
你想想看,同样的 1M 上下文,它用的计算量只有别人的几分之一。这不是「稍微优化了一下」,这是让百万 token 真正变得可用了。
之前 1M 上下文更多是个宣传噱头,实际跑起来慢得要死贵得要死。DeepSeek 这次让 1M 真正变得经济可行了。
就好比以前人人都说「我能跑马拉松」,但真的跑起来要么中途崩溃要么花三天,现在 DeepSeek 是真的能在合理时间内跑完全程的那种。
# 五、基准测试:谁赢在哪?
说到基准测试,这块就比较有意思了。
因为你会发现,三个模型在不同领域的表现,完全是不同的领跑者。
🏆 基准测试对比
| 基准测试 | 领先模型 | 得分 |
|---|---|---|
| SWE-Bench Verified | Claude | 87.6% |
| SWE-Bench Pro | Claude | 64.3% |
| Terminal-Bench 2.0 | GPT-5.5 | 82.7% |
| GDPval 知识工作 | GPT-5.5 | 84.9% |
| GPQA Diamond 科学推理 | Claude | 94.2% |
| LiveCodeBench 编程竞赛 | DeepSeek | 93.5% |
你发现了吗?
Claude 赢在「深度审查」,GPT-5.5 赢在「自主执行」,DeepSeek 赢在「编程竞技」。
没有万能模型了。
# 像体育一样:没有最强,只有最适合
这有点像体育。
篮球里有得分王、助攻王、防守王、篮板王。你不能说得分王就是「最强球员」,因为篮球不是只看得分。你也不能说某个位置上的最佳球员就一定比另一个位置上的强,因为不同位置的衡量标准完全不同。
AI 模型现在也是这样。GPT-5.5 是 Agentic 得分王,Claude 是推理防守王,DeepSeek 是性价比效率王。你说谁最强?这取决于你在打什么比赛。
# 模型路由:让合适的模型做合适的事
这也是为什么越来越多的团队开始搞模型路由了。
模型路由的意思就是,不同任务用不同模型。快速执行丢给 GPT-5.5,深度审查丢给 Claude,批量处理丢给 DeepSeek。
你不需要一个万能模型,你需要一个聪明的调度系统。就好比一个好教练不会让得分王去防守、让防守王去投三分,而是让每个人做自己最擅长的事。
# 六、争议:厂商自报的数字与隐藏的短板
再聊聊争议。
三个模型的基准测试,绝大部分是厂商自报的。这个。。。
坦率的讲,我每次看到厂商自报的数字,心里都会打个问号。
不是说我怀疑他们在造假,而是基准测试这件事本身就充满了方法论上的灰色地带。
# 基准测试的灰色地带
就好比高考分数,不同省的考卷不一样、难度不一样、评分标准不一样,你说哪个省的考生更强?其实很难直接比。
AI 基准测试也是这样。同一个 SWE-Bench Pro,不同的评估框架跑出来的分数可能差 5 到 10 个点。推理等级的选择也不同,GPT 的「xhigh」、Claude 的「max」、DeepSeek 的「Thinking」模式,其实不是完全对等的设置。
# Claude 的分词器坑
还有 Claude 的新分词器,这个挺坑的。
分词器啥意思呢,就是 AI 把文字切成「计费单位」的工具。就好比你去吃火锅,菜单上写着「羊肉 30 元」,但你不知道这 30 元是按盘算还是按斤算还是按片算。Claude 换了新的计价方式之后,同样的内容可能被切成更多的 token。
token 计数可能增加 1 到 1.35 倍,也就是说,虽然标价是$5/$25,但实际费用可能更高。你买了张机票标价 500,结果登机的时候发现行李超重加收 200,那种感觉。
我自己亲测用 Claude-opus 4.7 纯 API 写一个功能花了差不多 100 刀。不过确实好用,基本上一把过,不需要来回反复修改。不过即便这样,他比用其他模型写两遍的费用还贵一些。
# 各家短板
⚡ 各家短板对比
| 模型 | 短板 |
|---|---|
| Claude Opus 4.7 | 长上下文细节记忆退步(256K/1M needle-in-a-haystack 成功率不如 4.6);新分词器导致实际费用更高 |
| GPT-5.5 | 厂商自报分数,方法论灰色地带;推理等级设置不完全对等 |
| DeepSeek V4 | 生态工具链不成熟;幻觉控制未经大规模验证;Agentic 自主执行明显弱于闭源对手 |
Anthropic 宣称 Opus 4.7 是「最擅长深度推理的模型」,这个说法其实也有条件。有个测试叫 needle-in-a-haystack,就是在一大堆文字里藏一根针,看 AI 能不能找到。就好比给你一整本《辞海》,告诉你里面藏了一个错别字,看你能不能找出来。
有些独立开发者报告,在 256K 和 1M 这种超长文本里,Opus 4.7 找针的成功率反而不如上一代 4.6。长上下文里的细节记忆,退步了。
DeepSeek 的开源模型也有问题,生态工具链还不太成熟,就好比手机硬件参数很牛但 App Store 里没啥应用可用。幻觉控制也没经过大规模验证,Agentic 自主执行方面明显弱于两个闭源对手。
所以你看,每个模型都有它「不好意思大声说」的短板。
# 七、DeepSeek 的真正意义:改变游戏规则
说到 DeepSeek,我还想再多聊两句。
因为这可能是这三家里,对行业格局影响最深远的一家。
不是因为它最强,而是因为它改变了游戏规则。
# 第三个选择
之前闭源模型和开源模型的差距,大概是这样的。就好比买车,闭源模型是奔驰 S 级,五十万起步,体验顶级。开源模型是国产经济型,十万出头,体验还行但跟奔驰差着一大截。你预算够就买奔驰,预算不够就凑合用国产。
DeepSeek V4 Pro 把这个差距缩小到了「奔驰 S 级对奔驰 E 级减几个配置」的程度。SWE-Bench Verified 80.6%,GPQA Diamond 90.1%,LiveCodeBench 93.5%,这些数字跟闭源旗舰已经非常接近了。
然后它还开源了。MIT 协议。
然后它还便宜得离谱。$3.48/M 的输出价格。
这对行业的冲击是什么?
就是突然之间,你有了第三个选择。
之前的选择是,要么用贵的闭源旗舰,要么用便宜但差很多的开源模型。现在你有了一个便宜但几乎不差的开源模型。
好比以前买车只有两条路,五十万的奔驰或者十万的国产。现在突然冒出来一个十五万的,配置跟奔驰 S 级差不多,还送你全套维修手册让你自己改装。
这不是渐进式的进步,这是结构性改变了选项空间。
# 类比:电力革命
就像。。。
1880 年代,电力开始在美国普及,很多工厂主花大价钱买了发电机,装在工厂里。但装完之后发现,生产效率并没有显著提升。
因为他们只是用电动机替代了蒸汽机,整个工厂的布局、流程、管理方式都没有变。
那些真正吃到电力红利的人,是最早想明白电力到底是怎么回事的那波人。不是「用电力替代蒸汽力」,而是「因为有了电力,所以整个生产方式可以重新设计」。
DeepSeek 开源的意义,也不是「用一个更便宜的模型替代贵的模型」,而是「因为有了便宜的开源前沿模型,所以整个 AI 部署方式可以重新设计」。
# 自部署、私有化、定制化
你可以自部署了,就好比以前只能租房住,现在拿到图纸可以自己盖房子了。你可以私有化了,数据不用发送到别人的服务器了,就好比以前只能把钱存别人银行,现在可以自己建金库了。你可以针对自己的业务做定制化了,就好比以前只能买成衣,现在可以量身定制了。
这些事,在闭源模型时代,要么做不到,要么成本高得离谱。
现在,突然可以了。
# 八、怎么选?混着用
那到底怎么选呢?
我也不是什么权威,我自己也还在摸索,可能有些想法还不成熟。但基于我这一周的调研,大概是这样。
🎯 选型指南
| 使用场景 | 推荐模型 | 一句话总结 |
|---|---|---|
| 自主 Agent / 自动化工作流 / 终端操作 | GPT-5.5 | 最能独立干活的专员 |
| 代码审查 / 深度推理 / 视觉理解 / 长周期工程 | Claude Opus 4.7 | 最可靠的审查官 |
| 大规模处理 / 成本敏感 / 自部署 / 超长文档 | DeepSeek V4 Pro | 性价比无敌选择 |
但最聪明的做法,不是押注一个。
是混着用。
快速执行丢给 GPT,仔细审查丢给 Claude,批量处理丢给 DeepSeek。构建一个智能路由系统,让合适的模型做合适的事。
就好比一个聪明的主厨,切菜用最快的刀,熬汤用最稳的锅,装盘用最精细的镊子。不是一把刀干所有事,是每件事用最合适的工具。
这不是妥协,这是最优策略。
# 九、更大的信号:Agentic 时代到来
聊着聊着,我突然想到了一个更大的事。
这三个模型在 9 天之内密集发布,这件事本身就说明了一个趋势。
Agentic 时代正式到来了。
之前 AI 的竞争是「谁更聪明」,问答题做得更好,选择题得分更高。但现在三个模型的核心卖点全是「能替你做事」,不是「能回答你的问题」。
GPT-5.5 的 Terminal-Bench、OSWorld 全是 Agent 执行基准。Claude Opus 4.7 的卖点是在 Devin 里「能连贯工作数小时」。DeepSeek V4 专门做了 Agentic 能力优化。
AI 正在从一个「问答工具」变成一个「行动代理」。
这个转变,比任何一个单模型的性能提升都重要。
因为问答工具只能帮你想,行动代理能帮你做。想和做之间的距离,就是「知道怎么做」和「真的做完了」之间的距离。就好比你知道怎么修马桶和真的把马桶修好了之间的距离,这个距离,才是大多数人在工作中真正头疼的。
大时代啊,朋友们。
# 十、安全与能力的张力:三种价值观
最后再说一点我的感受。
这次三家同时出手,还有一个特别值得注意的趋势,就是安全与能力的张力越来越大。
🔒 安全策略对比
| 厂商 | 策略 | 比喻 |
|---|---|---|
| Anthropic | 宁可慢一点也要安全 | 核物理学家先建防护墙,再发布配方 |
| OpenAI | 分层释放,平衡安全和可用 | 处方药分级管理,有执照才能用强效版 |
| DeepSeek | 全开放,让社区自己负责 | 化学器材超市,方便合法者也方便风险者 |
Anthropic 手里有更强的 Mythos 模型,但选择了不放出来。就好比一个核物理学家手里有核弹的配方,但他选择先研究怎么建防护墙,而不是直接把配方贴在论坛上。他们在 Opus 4.7 上测试网络安全防护措施。
OpenAI 选择了分层防护,对一般用户限制网络安全能力,对通过验证的专业人员开放更多。就好比药店里的处方药,普通人只能买非处方版,有执照的医生才能拿到强效版。
DeepSeek 是 MIT 开源,安全保障最少,自由度最大,风险也最大。就好比把全套化学实验器材放在超市里随便买,方便了合法使用者,但也方便了可能搞出危险的人。
三种选择,三种价值观。
Anthropic 是「宁可慢一点也要安全」,OpenAI 是「分层释放平衡安全和可用」,DeepSeek 是「全开放让社区自己负责」。
我有时候觉得,这三种态度的背后,是对 AI 到底应该被怎么管理这件事的根本分歧。
这不是一个技术问题,这是一个文明问题。
我们到底想让 AI 变成什么?是一个被严格管控的工具,还是一个开放的公共基础设施,还是一个按需分配的分层服务?
三家给出了三种答案。
而真正的答案,可能还需要更多时间才能浮现。
以上,既然看到这里了,如果觉得不错,随手点个赞、在看、转发三连吧,如果想第一时间收到推送,也可以给我个星标 ⭐ ~
谢谢你看我的文章,我们,下次再见。
本站博文如非注明转载则均属作者原创文章,引用或转载无需申请版权或者注明出处,如需联系作者请加微信: geekmaster01